08.07.2014Q&A Wall at the OKFestival in Berlin
Some time ago the OKFestival asked for session proposals for this years conference in Berlin. I was at the conference last year in Geneva and enjoyed very much. It's just a nice atmosphere to talk to people from divers backgrounds (I'll get back to that in a minute).
Me and my colleagues from Liip thought about sessions for this years topic "Open Minds to Open Action". The Programme FAQs gave us some hints, what it takes for a session to be selected:
- Does the proposal advance the overall mission of the event
- Does the proposal offer participants a concrete, valuable outcome?
- Does the proposal advance the conversation around its area of open?
- Is the proposal interactive? – hint: slides and lectures strongly discouraged
- Does the proposal value or build on OKFestival’s principles of inclusivity and diversity?
Help newbies at the conference
We asked ourselves, how we can help people to connect to each other? We pictured a person that is interesting in the "Open Knowledge" topic but doesn't know any people at the conference. The first step is always the hardest. How do you find people that are interested in the same topics? Of course, one can attend sessions and try to talk to the people there.
But sometimes a little extra help is required. Some conference solve this problem by providing some kind of buddy system (e.g. the Chaos Mentors at the 30C3). The buddies are volunteers that show newbies around, and show them the venue, introduce them to people and so on. This is great for large conferences but might be an overkill for smaller ones.
As we were brainstorming about this we came up with the concept of a place, where everybody is encourages to write down his/her questions, so that others can pick that up and answer them right away or provide guidance. We first thought about doing this online using something like a twitter hashtag. But in the end, this is now why you went to a conference. You want to meet real people to talk face-to-face.
Q&A Wall to the rescue
So the challange is just, to find these people. To help making this asychronous, we developed the idea of a physical Q&A wall. This wall will be at the venue and provides space to write down questions (think of sticky notes or whiteboards to directly write on). Like that, this wall provides a meeting point or to simply read and write questions.
I'm very interested in how this wall is being used. Maybe Q&A is not the only thing that could be done with it. Everybody is invited to use that space. There are similar approaches to use such walls or boards to share news in local communities ("Community Chalkboards").
Btw: the Q&A Wall is also listed as a session at the OKFestival!
11.02.2014Usage of MongoDB with a spatial index and GeoJSON
During the Zurich Hacknights 2013 I was part of the team, that wanted to build a guide for monuments in Zurich. We were a large group of people with lots of ideas. Unfortunately I was the only web developer at that time, so I did my best to create a prototype of the guide called Denkmap.
There is a webservice (WFS) of the GIS-ZH containing all monuments of the Canton. I converted the source to GeoJSON using ogr2ogr:
wget -O DenkmalschutzWFS.gml http://maps.zh.ch/wfs/DenkmalschutzWFS?service=wfs&version=1.1.0&request=GetFeature&typeName=denkmalschutzobjekte
ogr2ogr -f geoJSON -s_srs EPSG:21781 -t_srs EPSG:4326 denkmal.geojson DenkmalschutzWFS.gml
I added the result as a layer to the map. This worked, but unfortunately the GeoJSON file is about 7MB. And each client has to download it. This takes time, especially on mobile devices not connected to a WLAN.
For a prototype this was okay, but how can we solve this for the future?
At this point it was clear that I need some part running on a server. This part must be able to divide all my data in reasonable chunks, that the client is able to download in a short time. Because I'm already dealing with GeoJSON and I didn't yet use MongoDB, I wanted to give it a try. I read that there is a spatial index and the possibility to run spatial queries. Hence, I had my perfect candidate. The other obvious solution would have been PostgreSQL with PostGIS. This would have worked too, but I wanted to try something new.
Import GeoJSON in MongoDB
This is quite easy if you respect the rules set by the mongoimport command:
- There used to be a
FeatureCollection, which basically is a big array. I removed it to get a list of objects. - Only use the MongoDB-supported subset of GeoJSON (i.e. Point, LineString and Polygon)
- The file must contain exactly one object per line, remove extra lines to make the importer happy
Once this is done, you can run the following to import your GeoJSON in a database called denkmap and a collection called wfsktzh:
mongoimport --db denkmap --collection wfsktzh < denkmal.geojson
mongo denkmap --eval "db.wfsktzh.ensureIndex({geometry: '2dsphere'})"
Create RESTful interface to consume the data
Once the data is save and sound in MongoDB, all you need is a script to expose exactly the data you need.
The Sinatra-like express framework helps to create the structure:
var express = require('express'),
geodata = require('./geodata.js'),
app = express(),
port = 3000;
app.get('/nearby/:lat/:lon', function(req, res) {
console.log(req.method + ' request: ' + req.url);
var lat = parseFloat(req.params.lat),
lon = parseFloat(req.params.lon);
geodata.nearby(lat, lon, function(docs) {
res.send(docs);
});
});
app.listen(port);
console.log('Listening on port ' + port + '...');
This allows us to query MongoDB using URLs like this: http://localhost:3000/nearby/47.3456/8.5432
The geodata.js contains the spatial query using $near. It returns all results in 1000m distance from the given coordinates (lat/lon). mongojs is a Node.js library for MongoDB:
var dbUrl = "denkmap",
coll = ["wfsktzh"],
db = require("mongojs").connect(dbUrl, coll);
exports.nearby = function(lat, lon, callbackFn) {
db.wfsktzh.find({
geometry: {
$near: {
$geometry : {
type: "Point",
coordinates: [lon, lat]
},
$maxDistance: 1000
}
}
},
function(err, res) {
callbackFn(res);
});
}
By the way: the project is still active and we are still looking for people to participate. The next step would be to connect DenkMap to WikiData and display some extra information, link to the corresponding Wikipedia page, and/or display images of the monument in the app.
31.01.2014Stop making stupid Open Data contests!
Disclaimer: I work for Liip, the company that build the Open Data pilot portal for Switzerland. I'm one of the developers of the portal. On the other hand, I'm a member of the opendata.ch association.
Although I'm a relatively new member of the Open Data community, I use and work with Open Data in different forms for many years now. I'm a keen enthusiast of the underlying idea of openness, collaboration and knowledge sharing. But the whole idea of Open Government Data (OGD) in Switzerland is currently broken. There are numerous problems and it probably all boils down to false expectations.
To make new data known to the public, often the first idea is to make an app contest. At first this sounds like a good idea: People working with your data and creating an app. It sounds like a win-win situation. Some may even think it's cheap way to get a lot of apps. The problem is, that contests have winners. And when there are winners, there must be losers. Your data is much too valuable, and every contribution is too important to waste time to choose a winner.
- You limit the interest in the data (why should I continue my project if I just lost a contest?).
- You limit the collaboration between the different groups that take part in the contest (why should I help somebody else to create a better app, if that decreases my chances to win this contest myself?).
The goal of an OGD data owner should be, that a lot of people know and use your data. This makes it worth to create this data in the first place. It doesn't matter if it is used by a special interest group or by an app used by millions of people.
On the other side, hackathons provide a good environment to play around, talk with different people and hack along. This is the kind of thing we need. Please understand that after such an event there are tons of ideas around. Prototypes, unfinished apps, visualizations etc. This is all very valuable. Don't expect a bunch of polished, ready-to-use apps as a result.
Most data owners consider it a failure if nothing happens after they release data. This is just plain wrong. The whole point of Open Data is to open your data. It's done. It's out there. Anyone that is interested can use this data. You never know when this is. Eventually someone creates a mashup, where you dataset is the missing piece.
What if this does not happen? It doesn't matter. Maybe the time was not right. Maybe this dataset is just not interesting enough. But that doesn't mean it was not worth to open it.
But of course there some things that you can and should do. Here is my little list of DOs and DON'Ts:
DO
- Talk about your data (speeches, blog posts)
- Make events to explain your data
- Bring cool swag to hackathons (for everyone!) :)
- Invite people to visit you, connect your experts with the community
- Provide help to process your data
- Open Source the tools you use internally to make them available for everybody
- Make sure to involve the media (yes, if you release your data or make an event, invite them)
- Coordinate with the community, ask questions, don't make assumptions
DON'T
- Measure the success of your Open Data by the amount of apps/visualization build with it. Actually, don't measure the success at all. Concentrate on releasing new and interesting data.
- Expect people to do your work
- Assume everybody was just waiting for your data and must be grateful for it. Give people time to discover your data
- Think that a press release is all it takes to get attention from the media
- If you have a budget for Open Data, don't spend it for someone to create an app with your data. Use it to organize events, invite people, do whatever you are best at!
- Seriously: No more contests, no more fucking prizes.
30.01.2014All new in 2014
Some time ago I started to fiddle with ruhoh, a static blog generator. I thought the idea of having static files as the interface to your website was intriguing.
When I started ruhoh was still beta (I don't remember the exact version number, but you can see for yourself if you want). The nice thing about ruhoh is, that it's still in development, and not all things just work. But the creator of ruhoh is available on Twitter or GitHub, so you can just ask, if something does not work.
Anyway, my early attempts to move from Tumblr to ruhoh never really made it past this fiddle phase. But when Tumblr announced a big DNS change and I found out that the DNS service I was using (XName) is really bad when I comes to changes, I lost my blog.
I used to blog under the domain readmore.ch. But this doesn't feel right anymore. I use my nickname 'odi' resp. 'metaodi' all over the interwebs. So why not use it for my blog?
Therefore I was once more looking into ruhoh, which in the meantime grew to a pretty good stable product (with still some fiddling if you want). So finally I created a new blog using ruhoh 2.6, imported my old Tumblr content here as markdown files and start all over again.
The fun part was to upgrade the ruhoh standard template to Bootstrap 3.
Now I got an up to date blog, which is even responsive.
The complete source can be found on GitHub.
Btw: I use GitHub Pages for the hosting and switched to DNSimple to provide my DNS service for metaodi.ch.
My plan for this blog is, that it should contain my opinion on various topics. It should not be too technical (I will write such content on other blogs, like the one of my company). It'll be mainly in English, but every once in a while I will write in German if needed (look out for the corresponding tag).
Happy reading and welcome to my new home!
23.05.2013On Citizenship in Open-source software development — Products I Wish Existed
https://medium.com/products-i-wish-existed/ddd1f7be1415
TL;DR: By giving an actual social status to the people contributing to a repository, GitHub would solve the problem of zombie-projects with …
11.10.2012Insert Coin To Play
Can gaming concepts help make OpenStreetMap better?
29.05.2012Fiddle around (code)
Since I’m using JavaScript more heavily, and beeing active on StackOverflow, I’m using a service called jsFiddle. It’s a great tool with a simple idea (I can see a pattern here: great tools are always based on simple ideas): Make it easy to write demo code. Either to help someone or to point out a problem.
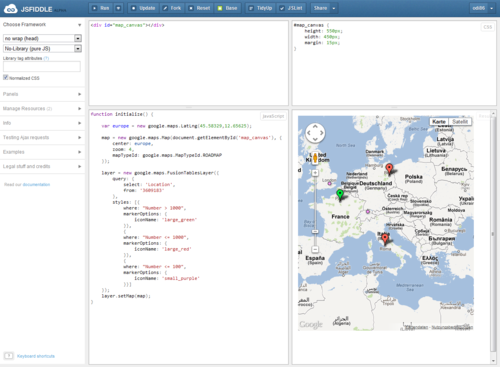
jsFiddle comes with a very basic user interface that is divided in 4 parts:
- Basic HTML (omitting
<head>and everything you don’t need) - CSS for styling
- JavaScript (the heart of the page)
- and finally the resulting page
No login required, just write your code and share the unique link. You can even include JavaScript frameworks or other external resources, it’s really easy!
Then last week I stumpled upon a website called sqlFiddle, which uses the basic idea of jsFiddle, but this time for databases and queries. There you can select different database systems and start writing your SQL code.
Now today I learned about a site called Sencha Fiddle, that let’s you actually develop Sencha Touch mobile application. You can even download the whole thing when your done. Wow!
There are several more xFiddle services that I can think of being valuable:
- LaTeX
- Shell scripting (allowing me to choose which shell I want: csh, ksh, bash, ..)
- Python
- Sass/SCSS
- Less
- ..
I don’t know if there is a directory of these services (leave me a message if you know it), but anyway I hope to see more websites like that in the future.
Spread the word. Start to code.
UPDATE I: There is a Python Fiddle :-)
UPDATE II: …and Ruby Fiddle (thanks Jürg)
UPDATE III: reFiddle for regular expressions (thanks Toni Suter)
08.03.2012Setup JavaScript unit testing using QUnit, PhantomJS and Jenkins on Amazon EC2
Me and my friend are currently working on a term paper about Google Fusion Tables. It’s about it’s possibilities and potential. Our goal is to create a cross-platform mobile application using Sencha Touch, therefore we need to write a lot of JavaScript code for the UI and to access the Google Fusion Tables. Fortunately Google provides an inofficial JSONP API, so we get native JavaScript access without another server roundtrip (there is a good blog post explaining the usage with jQuery).
The next question is: if we write tons of code in JavaScript, how are we going to unit test this code. We already used QUnit in a former project and it’s fairly easy to use, so we decided to use that. This all works very well, you get a nice web page where all your tests run in the browser and you get nice output, everything’s fine.

But, wait! What about our build? We use Jenkins CI, which is configured to build our project every time we push new code to GitHub. Wouldn’t it be nice if our tests run when we build, so we get immediate feedback and never ever forget to run them and fix our code?
Yes, it definitely would be!
Now we have several problems
- How do I run JavaScript without a browser?
- Does Jenkins “speak” JavaScript?
- Is there a solution for ant? Do I need another tool? Another server?
- How do I get my test results as XML, so Jenkins can handle them?
I checked serveral solutions to my this problems: From node.js to Rhino (there is even an ant based unit testing framework using Rhino) to TestSwarm. They were all too limited or too bloated. I couldn’t believe this is such a big deal to run QUnit JavaScript code, get the results and publish them in Jenkins.
This is when I found out about PhantomJS, a nice and handy headless WebKit browser, that runs JavaScript code. Exactly what I need. As we are using Amazon EC2 for this project, I tried to install PhantomJS on a basic Amazon AMI. I just couldn’t get it to work, when I asked in Twitter if someone succeeded to setup PhantomJS. Philipp Küng pointed out (thanks again!) that it is much easier to setup with Ubuntu. Well then, launch a new Instance on EC2, choose the latest Ubuntu AMI, and after some simple commands you’re good to go:
sudo add-apt-repository ppa:jerome-etienne/neoip
sudo apt-get update
sudo apt-get install phantomjs
After that I had to setup Xvfb (virutal framebuffer), because EC2 instances are headless. Generally see the PhantomJS Wiki for further information.
Now I have a PhantomJS instance, the published QUnit tests and Jenkins. To be able to retrieve the data from PhantomJS I created a simple PHP script, which runs on the new instance and just executes a shell command (idea from this blog post).
<?php
/* Display 99 is configured on the server using Xvfb */
$value = shell_exec("DISPLAY=:99 phantomjs run_qunit.js http://gft.rdmr.ch/test/js/index.html junit-xml");
echo $value;
?>
With this URL I was able to create a simple ant target, which fetches the latest results from the tests:
<target name="test-js" depends="deploy">
<get src="${test.url}" dest="${result.dir}/${result.js.file}"/>
</target>
Where ${test.url} referes to my PHP script, and ${result.dir} is
configured as the location of JUnit reports in Jenkins (see screenshot):

Now the last missing piece is to get proper output for Jenkins. I
adapted the QUnit test
runner
from the PhantomJS examples accordingly (called run_qunit.js, see
above, here is my
version).
I added a new command line parameter type, which determines the type
of output the runner generates. With the value junit-xml, the output
can directly be used by Jenkins, this is the reason for the junit-xml
parameter in the PHP script above.
The generated XML looks like that:
<?xml version="1.0"?>
---
Tests completed in 2294 milliseconds.
36 tests of 36 passed, 0 failed.
---
<testsuite name="QUnit - JavaScript Tests" timestamp="2012-03-08T00:11:27Z" tests="36" failures="0" time="2.294">
<testcase name="PaintSwitzerland" classname="GoogleFusionTable">
</testcase>
<testcase name="Construtor" classname="GftLib">
</testcase>
<testcase name="Constants" classname="GftLib">
</testcase>
<testcase name="doGet" classname="GftLib">
</testcase>
<testcase name="doPost" classname="GftLib">
</testcase>
<testcase name="doGetJSONP" classname="GftLib">
</testcase>
<testcase name="doPostJSONP" classname="GftLib">
</testcase>
<testcase name="ExecSelect" classname="GftLib">
</testcase>
</testsuite>
And in Jenkins like that: 
Overview of tests: 
Failed test: 
06.10.2011ZFF 2011: Turn Me On, Goddammit

In "Turn Me On, Goddammit" von Jannicke Systad Jacobsen spielt die bemerkenswerte Helene Bergsholm die 15jährige Alma, welche gerade dabei ist ihre Sexualität zu entdecken. Sie wohnt mit ihrer Mutter in einem Provinznest in Norwegen. An einer Party ereignet sich ein peinlich Vorfall mit ihrem Schwarm Artur, welchen sie brühwarm ihren Freundinnen erzählt (“He poked me with his penis!”). Niemand will ihr diese Geschichte glauben, fortan wird sie zur Aussenseiterin, die Lügengeschichten verbreitet.
Auch der Zuschauer des Film wird geschickt darüber im Unklaren gelassen, ob dieses Ereignis tatsächlich stattgefunden hat oder nicht. Die Kamera schweift manchmal ins träumerische ab, indem der Fokus auf dem Vordergrund liegt und der Hintergrund stark verschwommen wird oder die Farbgebung ganz stark ist. Dieses Stilmittel setzt die Regisseur immer dann ein, wenn die Hauptdarstellerin in ihrer Fantasie ist, jedoch manchmal auch bei Ereignissen die tatsächlich stattfinden. Dadurch erscheint auch die ganze Welt des Dorfes mal romantisch, mal langweilig.
Die Hauptdarstellerin ist eine Wucht, diese junge Frau weiss genau was sie will und bewegt sich sehr natürlich vor der Kamera, das Thema Sexualität ist einfach eine Facette ihres (pubertären) Charakters, der weder übertrieben wirkt noch ins Lächerliche gezogen wird.
Leichte Erzählweise, kurzweilige, gute Unterhaltung.